Splash

Splash is a javascript rendering service with an HTTP API. It’s a lightweight browser with an HTTP API, implemented in Python 3 using Twisted and QT5.
Installation¶
First we need to install and luch docker in order to use splash, the exact steps can be found in the documentation here
Once the docker is running in the host we can access the server and check if it is working, in this case we can go to "localhost:8050"
Configuration¶
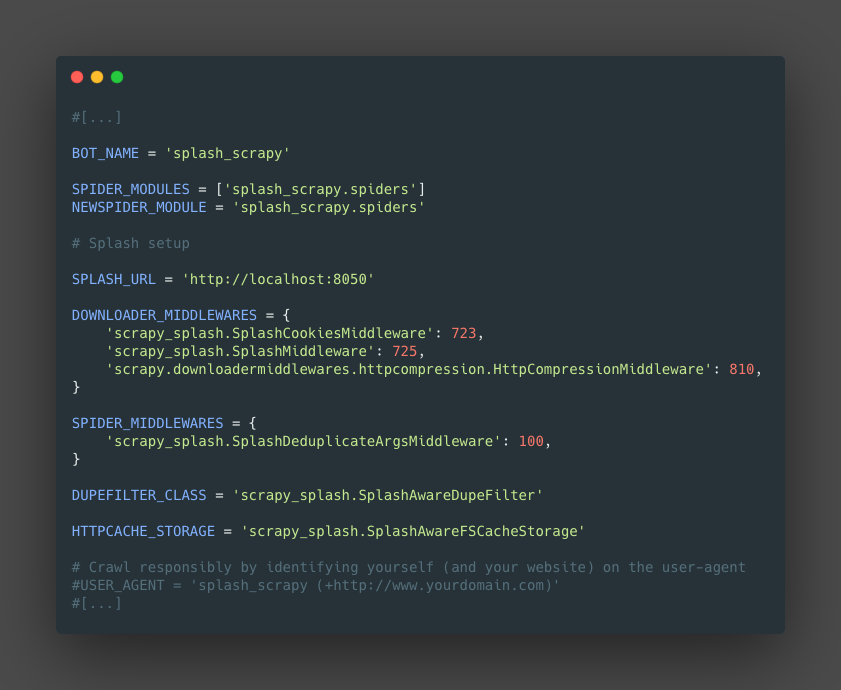
We need to make some changes on the project settings settings.py
1. Adding the splash server to the project¶
settings.py
2. Add and Enable the splash middleware¶
settings.py
3. Add and Enable the spider middleware¶
settings.py
4. Set the custome DUPEFILTER_CLASS¶
settings.py
5. Set the HTTPCACHE_STORAGE¶
settings.py
Steps (4) and (5) are necessary because Scrapy doesn't provide a way to override request fingerprints calculation algorithm globally; this could change in future.