Transfer Learning
Preparing pre-trained model¶
Transfer Learning is basically use pre-trained models as base for our models, those pre-trained models in most of the cases have been train with millions of samples and the have been improve for specialist in the field. In most of the cases use this transfer learning will reduce the implementation time and increase the value of the result obtained.
For this example we will use a model called InceptionV3
The Inputs¶
We will need to do some manipulation of the model the layers of the pre-train model, we need to changes the weights as well as some layers, for that we need to import coupe things
Import the pre-trained model¶
we need some new weight, in this case we can get those new weights from
https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
- We will import the model.
- We will create a variable to hold the new pre-trained weights.
- Create the
pre_trained_modelbe aware ofinclude_tope=Falseandweights=None. Inception model has a dense connected layer on the top, and we dont need it so withinclude_tope=Falsewe can remove that dense layer.weights=Nonetell the model that we will use our own weights.
Lock layers¶
Now, we don't need to retrained the layers on the pre_trained_model, so we need to lock that layer so they are not going to be trained, for that we will go layer by layer locking them up.
Adding our own code¶
To add our own code first we need to know which is the last layer, in this model the last layer is a convolution of \(3x3\) but we can get other layers and use it as last layer, to do that we will use the names of the layers, yes the layers have a name, so we can get them using the names, in this, case we will use the layer called mixed7
Defining a new model¶
To define the new model we will use the last layer of the previous steps and some new layers, few things to be aware of, we will use a slightly different syntax, but we will just adding new layers to the model. Once we have all the layers we will use the abstract class Model to create our new model.
- We flatten the last_output that is what is coming form the pre-trained model.
- Create a dense layer.
- Create a last Dense layer that will be the output of the whole model.
- Use the abstract class
Modelto create the new model, we pass the input of the pre-trained model and the layer definition we did in the previous steps.
Augmentation and fitting¶
We don't need to change anything form the augmentation and the fitting section.
just a remainder of the augmentation we did before.
We will see that we are having an over-fitting case.
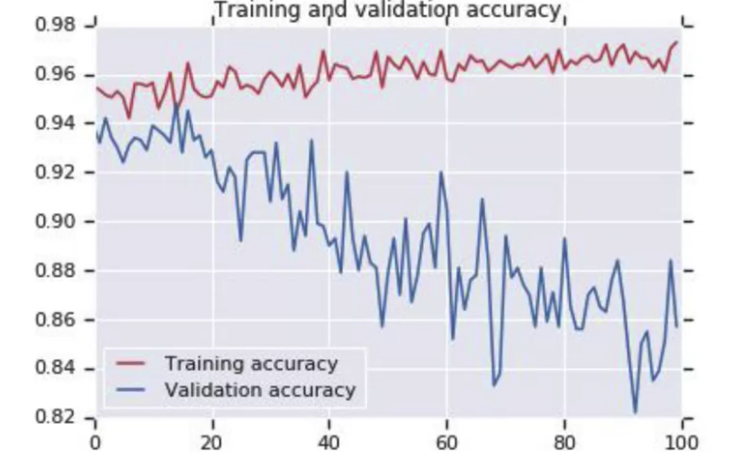
Dropout Layers¶
In some cases we will have some over-fitting after the image augmentation, so it is a good practice to have some Dropout Layers, this layer will randomly turn off and on some of the neurones in the layers, preventing the over-fitting.
Dropout layers are Regulazers
the dropout layer will look like this:
0.2 tell the model to drop up to 20% of the neurons.
so the code will be:
the full model in this Colab
34277d71620fd6e8b442837ae1bc3d161014df4e