Introduction

An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way.
Install¶
We can install it using pi
Project structure¶
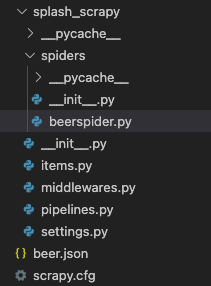
From here there are 3 important items
Spiders¶
In this folder we will create the specific class that represent the spiders.
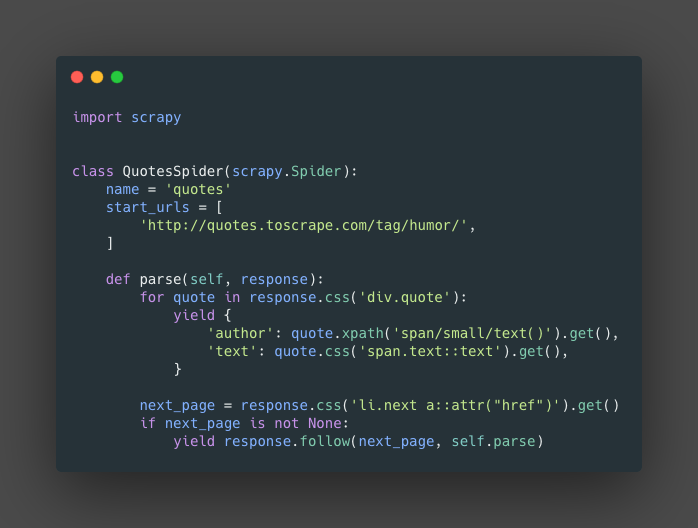
namethis is the specific name of the spider.start_urlsthis is the list of starting URLs to be crawl.parse()this is the main function that will get the items from the response object that contain the webpages.- The next part is to handle the pagination of some pages. First create
next_pageis a variable storing the selector for the button for the next page. the second part is a conditional that will check if there is a next page. the third, Use the functionfollow()this will received the selectornext_pageand a callback function, in this caseparse().
items¶
This script will hold the items and the itemloaders.
The items will hold the information that we scrap, after the Itemloaders clean them. there will be some changes in the spiders and in the items.py files.
Bellow some examples
project/spider/whiskyspider.py
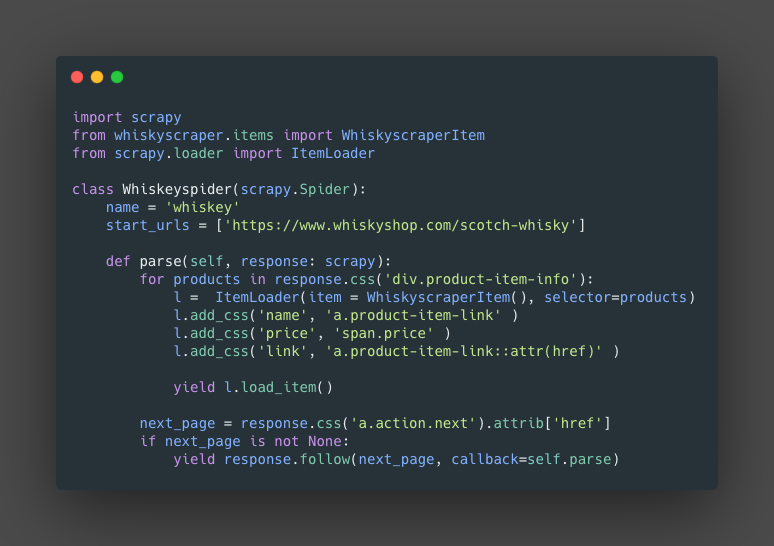
- Imports: We need to import, First, the item class for the specific spider
from whiskyscraper.items import WhiskyscraperItem. Second, we import the scrapy item loaderfrom scrapy.loader import ItemLoader. - parse(): We need to create an instance of the
ItemLoaderthis will received two parameters, first the item class, in this caseWhiskyscraperItem()and a selector.l = ItemLoader(item = WhiskyscraperItem(), selector=products)where productsfor products in response.css('div.product-item-info'):. - Finally we
yieldthel.load_item()(Basically load the clean information on the item).
project/items.py
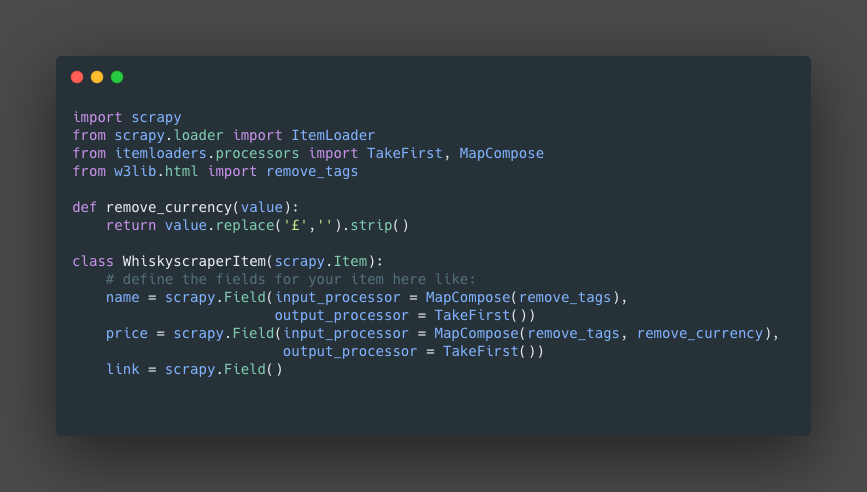
from scrapy.loader import ItemLoader: we will import the IteamLoader, this will allow use to access processors and functions to clean the data.from itemloaders.processors import TakeFirst, MapCompose: This are two functions that we will use in theinput_processorandout_processor.MapCompose()allow me to run several functions on the incoming data.from w3lib.html import remove_tags: withremove_tags()will help use to remove the html tags from the information.remove_currency(): this is an example of a custom function that we will use to clean the information and later will be use inMapCompose().Field(): Here we will use theinput_processorandoutput_processorto clean the information.
Commands¶
Create the project
Create the spider
Data flow¶
This information was extracted fro the official website and all the rights belong to then. I copy part of the information since it is relevant to understand how scrapy handle the data flow.
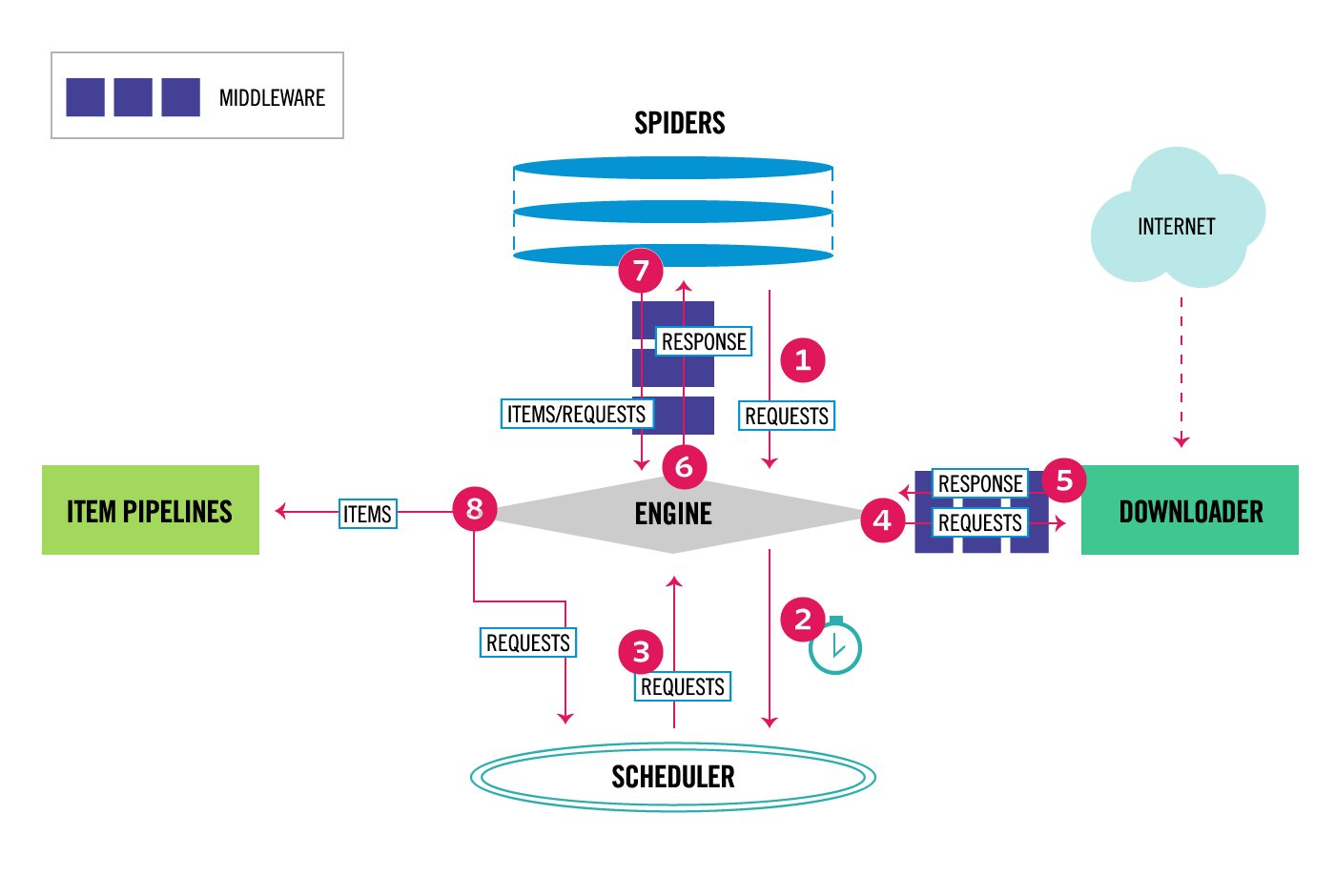
- The Engine gets the initial Requests to crawl from the Spider.
- The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.
- The Scheduler returns the next Requests to the Engine.
- The Engine sends the Requests to the Downloader, passing through the Downloader Middlewares (
process_request()). - Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middlewares (
process_response()). - The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (
process_spider_input()). - The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine, passing through the Spider Middleware (
process_spider_output()). - The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks for possible next Requests to crawl.
- The process repeats (from step 1) until there are no more requests from the Scheduler.
Components¶
Scrapy Engine¶
Responsible to control the data flow between all components.
Scheduler¶
The scheduler receive the original request from the engine from the engine and enqueue so it can be use later, when the engine want it.
Downloader¶
This component is the responsible to fetch the web pages and feeding them to the engine, who will feed it to the spiders.
Spider¶
This are the custom classes use to parse the response and extract the items form it.
Item pipeline¶
This will take care of cleaning the information that the spider extracted.
Downloader Middlewares¶
from the original documentation Downloader middlewares are specific hooks that sit between the Engine and the Downloader and process requests when they pass from the Engine to the Downloader, and responses that pass from Downloader to the Engine.
Spider Middlewares¶
from the original documentation Spider middlewares are specific hooks that sit between the Engine and the Spiders and are able to process spider input (responses) and output (items and requests).
Scrapy Shell¶
Scrapy provide an interactive Shell that we can use to test or gather information of the website we will scrap.
to start:
Here in the shell we can use the function fetch() passing the URL, this will download the page, and we will be able to interact with it using the response object and then we can use selectors to scrap the information, example response.css('a.product')